I really don’t care how any given A/B test turns out.
That’s right. Not one bit.
But wait, how do I double or triple conversion rates without caring how a test performs?
I actually care about the whole SYSTEM of testing. All the pieces need to fit together just right. If not, you’ll waste a ton of time A/B testing without getting anywhere. This is what happens to most teams.
But if you do it right. If you play by the right rules. And you get all the pieces to fit just right, it’s simply a matter of time before you triple conversions at any step of your funnel.
I set up my system so that the more I play, the more I win. I stack enough wins on top of each other that conversion rates triple. And any given test can fail along the way. I don’t care.
What does my A/B testing strategy look like? It’s pretty simple.
- Cycle through as many tests as possible to find a couple of 10-40% wins.
- Stack those wins on top of each other in order to double and triple conversion rates.
- Avoid launching any false winners that drag conversions back down.
For all this to work, you’ll need to follow 7 very specific rules. Each of them is critical. Skip one and the whole system breaks down. Follow them and you’ll drive your funnel relentlessly up and to the right.
Rule 1: Above all else, the control stands
I look at A/B tests very differently from most people.
Usually, when someone runs a test, they’ll consider each of their variants as equals. The control and the variant are both viable and their goal is to see which one is better.
I can’t stand that approach.
We’re not here for a definitive answer. We’re here to cycle through tests to find a couple of big winners that we can stack on top of each other.
If there’s a 2% difference between the variant and the control, I really don’t care which one is the TRUE winner. Yes, yes, yes, I’d care about a 2% win if I had enough data to hit statistical significance on those tests (more on this in a minute). But unless you’re Facebook or Amazon, you probably don’t have that kind of volume. I’ve worked on multiple sites with more than 1 million visitors/month and it’s exceedingly rare to have enough data hitting a single asset in order to detect those kinds of changes.
In order for this to system to work, you have to approach the variant and control differently. Unless a variant PROVES itself as a clear winner, the control stands. In other words, the control is ALWAYS assumed to be the winner. The burden of proof is on the variant. No changes unless the variant wins.
This ensures that we’re only making positive changes to assets going forward.
Rule 2: Get 2000+ people through the test within 30 days
So you don’t have any traffic? Then don’t A/B test. It’s that simple. Do complete revamps on your assets and then eyeball it.
Remember, we need the A/B testing SYSTEM working together. And we’re playing the long-term. Which means we need a decent volume of data so we can cycle through a bunch of different test ideas. If it takes you 6 months to run a single test, you’ll never be able to run enough tests to find the few winners.
In general, I look for 2000 or more people hitting the asset that I’m testing within 30 days. So if you want to A/B test your homepage, it better get 2000 unique visitors every month. I even prefer 10K-20K people but I’ll get started with as little as 2000/month. Anything less than that and it’s just not worth it.
Rule 3: Always wait at least a week
Inside of a week, data is just too volatile. I’ve had tests with 240% improvements at 99% certainty within 24 hours of launching the test. This is NOT a winner. It always comes crashing down. Best-case scenario, it’s really just a 30-40% win. Worse case, it flip-flops and is actually a 20% decline.
It also lets you get a full weekly cycle worth of data. Visitors don’t always behave the same on weekends as they do during the week. So a solid week’s worth of data gives you a much more consistent sample set.
Here’s an interesting result that I had on one of my tests. Right out of the gate, it looked like I a had 10% lift. After a week of running the test, the test does a COMPLETE flip-flop on me and becomes a 10% loser (at 99% certainty too):
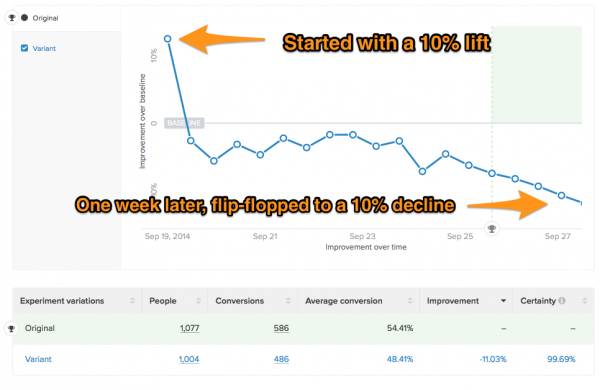
One of my sneaking suspicions is that most of the 250% lift case studies floating around the interwebs are just tests that had extreme results in the first few days. And if they had ran a bit longer, they would have come down to a modest gain. Some of them would even flip-flop into losers. But because people declare winners too soon, they run around on Twitter declaring victory.
Rule 4: Only launch variants at 99% statistical significance
Wait, 99%? What happened to 95%?
If you’ve done an A/B test, you’ve probably run across the recommendation that you should wait until you hit 95% significance. That way, you’ll only pick a false winner 1 out of every 20 tests. And none of us want to pick losers so we typically follow this advice.
You’ve run a bunch of A/B tests. You find a bunch of wins. You’re proud of those wins. You feel a giant, happy A/B testing bubble of pride.
Well, I’m going to pop your A/B testing bubble of pride.
Your results didn’t mean anything. You picked a lot more losers than just 1 in 20. Sorry.
Let’s back up a minute. Where does the 95% statistical significance rule come from?
Dig up any academic or scientific journal that that has quantitative research and you’ll find 95% statistical significance everywhere. It’s the golden standard.
When marketers started running tests, it was a smart move to use this same standard to see if our data actually told us anything. But we forgot a key piece along the way.
See, you can’t just run a measure of statistical confidence on your test after it’s running. You need to determine your sample size first. We do this by deciding the minimal improvement that we want to detect. Something like 5% or 10%. Then we can figure out the statistical power needed and from there, determine our sample size. Confused yet? Yeah, you kind of need to know some statistics to do this stuff. I need to look it up in a textbook each time it comes up.
So what happens if we skip all the fancy shmancy stats stuff and just run tests to 95% confidence without worrying about it? You come up with false positives WAY more frequently than just 1 out of 20 tests.
Here’s an example test I ran. In the first two days, we got a 58.7% increase in conversions at 97.7% confidence:
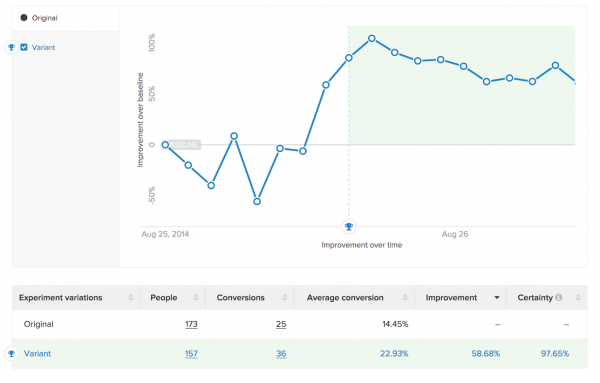
That’s more than good enough for most marketers. Most people I know would have called it a winner, launched it, and moved on.
Now let’s fast-forward 1 week. That giant 58.7% win? Gone. We’re at a 17.4% with only 92% confidence:

And the results after 4 weeks? Down to a 11.7% win at 95.7% certainty. We’ve gone from a major win to a marginal win in a couple of weeks. It might stabilize here. It might not.
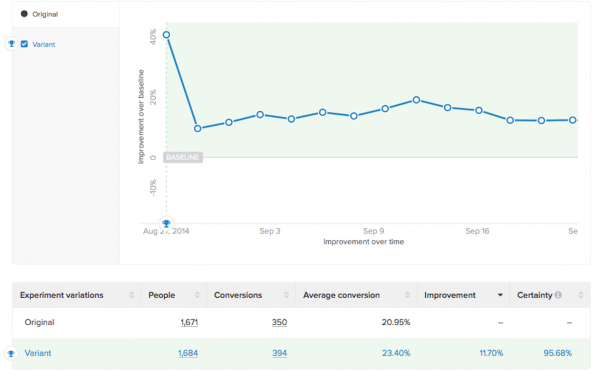
We have tests popping in and out of significance as they collect data. This is why determining your required sample size is so important. You want to make sure that a test doesn’t trick you early on.
But Lars! It still looks like a winner even if it’s a small winner! Shouldn’t we still launch it? There are two problems with launching early:
- There’s no guarantee that it would have turned out a winner in the long run. If we had kept running the test, it might have dropped even further. And every once in awhile, it’ll flip-flop on you to become a loser. Then we’ve lost hard-earned wins from previous winners.
- We would have vastly over-inflated the expected impact on the business. A 60% win moves mountains. They crush your metrics and eat board decks for breakfast. 11% wins, on the other hand, have a much gentler impact on your growth. They give your metrics a soothing spa package and nudge them a bit in the right direction. Calling that early win at 60% gets the whole team way too excited. Those same hopes and dreams get crushed in the coming weeks when growth is far more modest. Do that too many times and people stop trusting A/B test results. They’ll also take the wrong lessons from it and start focusing on elements that don’t have a real impact on the business.
So what do we do if 95% statistical significance is unreliable?
There’s an easier way to do all this.
While I was at Kissmetrics, I worked with our Growth Engineer, Will Kurt, at the time. He’s a wicked smart guy that runs his own statistics blog now.
We modeled out a bunch of A/B testing strategies over the long term. There’s a blog post that goes over all our data and I also did a webinar on it. How does a super disciplined academic research strategy compare to the fast and lose 95% online marketing strategy? What if we bump it to 99% statistical significance instead?
We discovered that you’d get very similar results over the long term if you just used a 99% statistical significance rule. It’s just as reliable as the academic research strategy without needed to do the heavy stats work for each test. And using 95% statistical significance without a required sample size isn’t as reliable as most people think it is.
The 99% rule is the cornerstone of my A/B testing strategy. I only make changes at 99% statistical significance. Any less than that and I don’t change the control. This reduces the odds of launching false winners to a more manageable level and allows us to stack wins on top of each other without accidentally negating our wins with a bad variant.
Rule 5: If a test drops below a 10% lift, kill it.
Great, we’re now waiting for 99% certainty on all our tests.
Doesn’t that dramatically increase the time it takes to run all our tests? Indeed it does.
Which is why this is my first kill rule.
Again, we care about the whole system here. We’re cycling to find the winners. So we can’t just let a 2-5% test run for 6 months.
What would you rather have?
- A confirmed 5% winner that took 6 months to reach
- A 20% winner after cycling through 6-12 tests in that same 6 month period
To hell with that 5% win, give me the 20%!
So the longer we let a test run, the higher that our opportunity costs start to stack up. If we wait too long, we’re forgoing serious wins that we could of found by launching other tests.
If a test drops below a 10% lift, it’s now too small to matter. Kill it. Shut it down and move on to your next test.
What if we have a 8% projected win at 96% certainty? It’s SO close! Or what if we have enough data to find 5% wins quickly?
Then we ask ourselves one very simple question: will this test hit certainty within 30 days? If you’re 2 weeks into the test and close to 99% certainty, let it run a bit longer. I do this myself.
What happens at day 30? That leads us to our next kill rule.
Rule 6: If no winner after 1 month, kill it.
Chasing A/B test wins can be addictive. JUST. ONE. MORE. DAY. OF. DATA.
We’re emotionally invested in our idea. We love the new page that we just launched. And IT’S SO CLOSE TO WINNING. Just let it run a bit longer? PLEEEEEASE?
I get it, each of these tests becomes a personal pet project. And it’s heartbreaking to give up on it.
If you have a test that’s trending towards a win, let it keep going for the moment. But we have to cut ourselves off at some point. The problem is that a many of these “small-win” tests are mirages. First they look like 15% wins. Then 10%. Then 5%. Then 2%. The more data you collect, the more that the variant converges with your control.
CUT YOURSELF OFF. We need a rule that keeps our emotions in check. You gotta do it. Kill that flop of a test and move on to your next idea.
That’s why I have a 30-day kill rule. If the variant doesn’t hit 99% certainty by day 30, we kill it. Even if it’s at 98%, we shut it down on the spot and move on.
Rule 7: Build your next test while waiting for your data
Cycling through tests as fast as we can is the name of the game. We need to keep our testing pipeline STACKED.
There should be absolutely NO downtime between tests. How long does it take you to build a new variant? Starting with the initial idea, how long until it goes live? 2 weeks? 3 weeks? Maybe even an entire month?
If you wait to start on the next test until the current test is finished, you’ve wasted enough data for 1-2 other tests. That’s 1-2 other chances that you could of found that 20% win to stack on top of your other wins.
Do not waste data. Keep those tests running at full speed.
As soon as one test comes down, the next test goes up. Every time.
Yes, you’ll need to get a team in place to dedicate to A/B tests. This is not a trivial amount of work. You’ll be launching A/B tests full time. And your team will need to be moving at full-speed without any barriers.
If it were easy, every one would be doing it.
Follow All 7 A/B Testing Rules to Consistently Drive Conversion Up and to the Right
Follow the system with disciple and it’s a matter of time before you double or triple your conversion rates. The longer that you play, the more likely you’ll win.
Here are all the rules in one spot:
- Above all else, the control stands
- Get 2000+ people through the test within 30 days
- Always wait at least a week
- Only launch variants at 99% certainty
- If a test drops below a 10% lift, kill it.
- If no winner after 1 month, kill it.
- Build your next test while waiting for your data